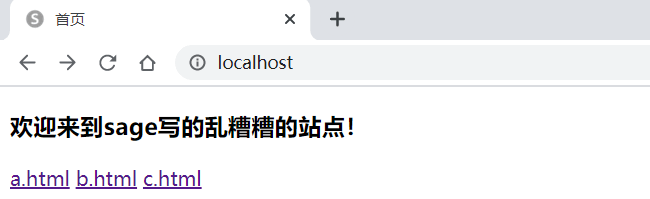
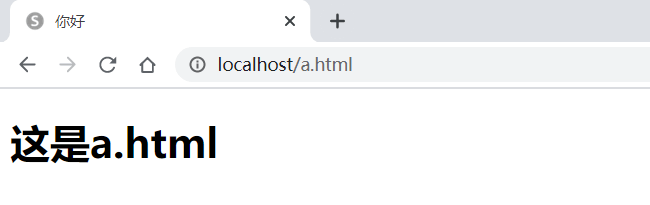
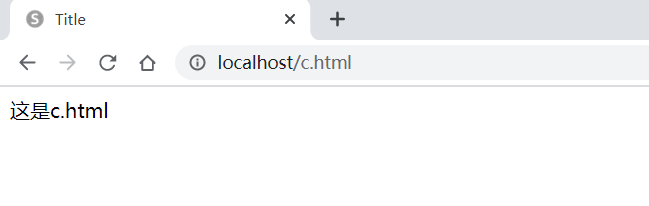
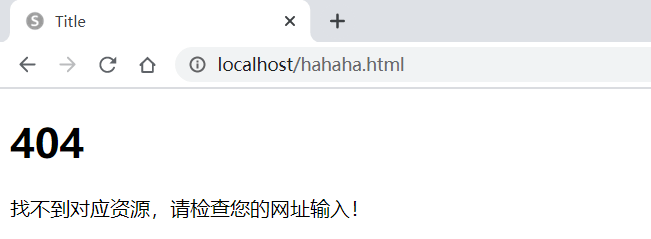
建立响应目录
通过不断的努力已经成功开发了一个HTTP服务器,但是对于当前服务器开发有一个问题,所有的请求都只能得到一个统一的内容响应:
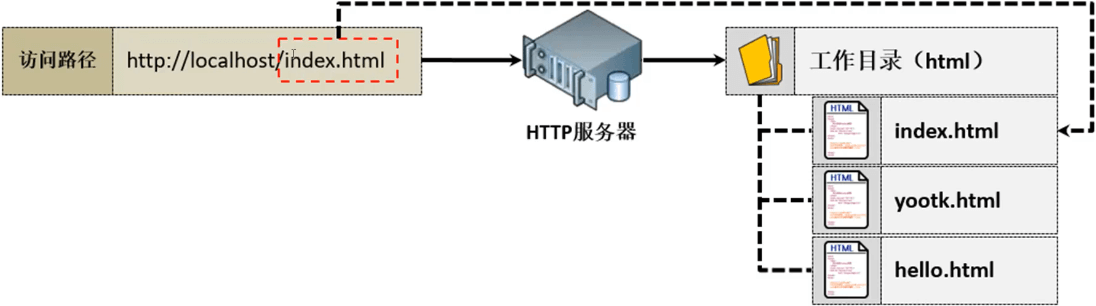
如果这些代码直接以字符串的形式出现在整个的Python程序里面,那么这样的HTML代码是很难被我们前端进行维护的,前端需要的是一个可以进行响应的处理目录,相当于建立一个专属的html响应代码目录,而后所有要响应的内容都保存在此目录之中,根据用户请求的路径来进行内容的加载。
测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
import socket
import multiprocessing
import re
import os
HTML_ROOT_DIR = os.getcwd() + os.sep + "template"
class HTTPServer:
def __init__(self,port):
self.server_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(("0.0.0.0",port))
self.server_socket.listen()
def start(self):
while True:
client_socket,client_address = self.server_socket.accept()
print("[新的客户端连接]客户端IP:%s、访问端口:%s" % client_address)
handle_client_process = multiprocessing.Process(target=self.handle_response,
args=(client_socket,))
handle_client_process.start()
def handle_response(self,client_socket):
request_headers = client_socket.recv(1024)
try:
file_name = re.match(r"\w+ +(/[^ ]*)", request_headers.decode().split("\r\n")[0]).group(1)
print("请求文件:%s" % file_name)
if file_name == "/":
file_name = "/index.html"
if file_name.endswith(".html") or file_name.endswith(".htm"):
client_socket.send(bytes(self.get_html_data(file_name),"UTF-8"))
else:
client_socket.send(self.get_binary_data(file_name))
except:
client_socket.send(bytes(self.get_html_data("/404.html"), "UTF-8"))
client_socket.close()
def get_binary_data(self,file_name):
response_body = self.read_file(file_name)
return response_body
def read_file(self,file_name):
file_path = os.path.normpath(HTML_ROOT_DIR + file_name)
file = open(file_path,"rb")
file_data = file.read()
file.close()
return file_data
def get_html_data(self,file_name):
response_start_line = "HTTP/1.1 200 OK\r\n"
response_headers = "Server:giiiServer\r\nContent-Type:text/html\r\n"
response_body = self.read_file(file_name).decode("UTF-8")
response = response_start_line + response_headers + "\r\n" + response_body
return response
def main():
http_server = HTTPServer(80)
http_server.start()
if __name__ == "__main__":
main()
|
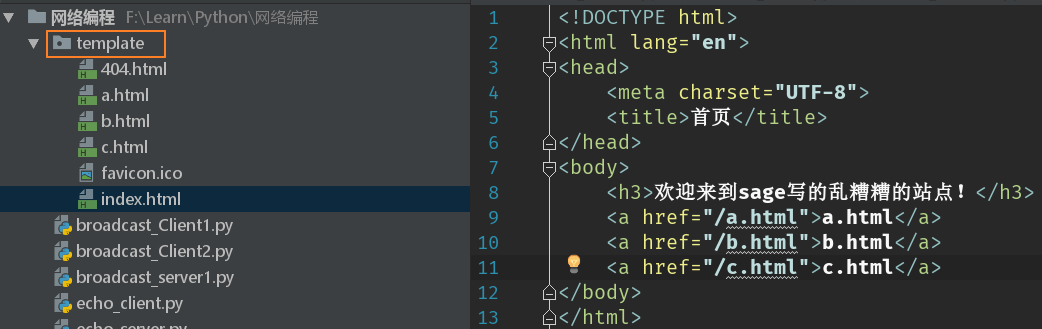
此时会根据用户的请求路径找到指定的文件进行内容的加载并将此内容返回给用户,如果要进行页面维护的话,只需要修改html文件目录中的程序即可。
测试结果